The challenge at hand
Learning is doing in the fast pacing word of information technology, even if your day job does not involve much coding anymore. So when I thought a little while ago of an use case that could benefit from the use of an agentic workflow to optimize its process I had to give it a go. The use case in question is one that seems for some maybe like a deceptively easy to perform process of collecting -and enriching data, but which can be a notorious cumbersome and expensive process to execute.
So after some research I picked LlamaIndex to give it a go to tackle the challenge at hand, which is sourcing data about food establishments from for example the internal data sources you have at your company, harmonize and lastly enrich the data with a single newly created data point that is needed to create an unique data set that could be used further down stream within for example your marketing -and sales processes.
For good order, picking an agentic framework and other components needed like a LLM and vector database in your organization can be a daunting task considering all the variables in question to take into account in the fast changing landscape of AI, like of course security and compliance. But I leave that out of scope of this write up, although I certainly have some opinions and lessons learned to share at a later moment.
The solution
But LlamaIndex seems easy enough to learn for this exercise, with a large community and documentation at hand, it is known for excelling at data integration with an agentic workflow with a broad variaty of connectors available, which fits the bill. I initially started coding the basics of the application manually to get hands on with developing agentic workflows, but I very quickly got Claude Code (in VS Code) involved. This exercise with a LLM as my coding buddy, which maybe took me a few hours at most to go back and forth with Claude Code and let it build, refactor and deploy code is as expected tremendously helpful and productive. In general I find the approach of specifying the software architecure you want to put in place upfront, that you can do in conversation with Claude or Codex for that matter, a really powerfull way of putting iteratively an application together. You can steer the build of the solution into the direction you see fitt together with the feedback of the LLM, and then zoom in on specific topics in your architecture so that from a contextual point of view the LLM is focussed on the topics you want to have addressed which makes it more effective and less error proun. The future of software development is here for sure.
Back to the use case at hand. The requirements:
- Have a single master data set of food establishment data
- Enrich the data with a Place Id and an Occassion identifier that best fits a respective food estbalishment.
- Have an user interface by which the collected source data can be uploaded that trickers the process to enrich and store the data in a central database.
- The original record id of the uploaded source data merged into the master data set needs to be retained and a new unique record id to be created of a newly created harmonised master data record.
This is the workflow of the agentic solution build to fulfil these requirements:
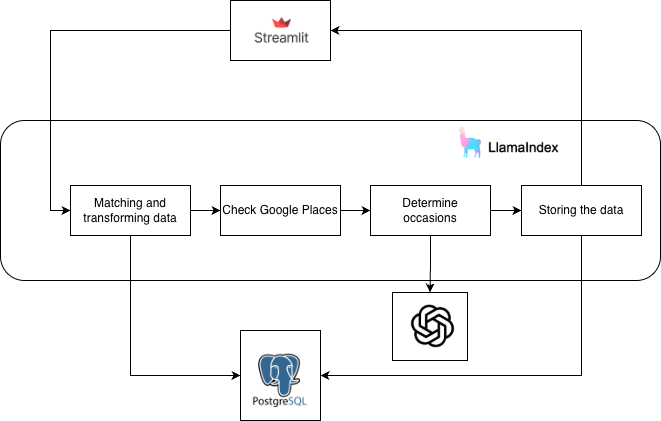
Some notes:
- I skipped some critical topics relevant for a solid production grade solution, like authentication, authorization and observability for the purpose of this exercise.
- I used Postgres on my local machine, but you could also run the full solution in for example a Databricks App environment and have it connected to Lakebase that supports Postgress connectivity, or for example connect it to a Supabase database instance.
- The solution can be extended with for example a human in the loop workflow step to validate data records that do not comply to a certain data quality treshold.
- When to use finetuning or prompting or working with skills and plugins are solution architecture desisions that always need to be considered, but in this showcase this isn’t fully explored. I can certainly see scenarios where one would consider the use of for example locale SLM’s to build up something proprietary within the boundaries of your companies IT infrastructure.
- Managing the master data set stored in the database manually can be further build into the solution.
- I used Streamlit for the frontend, but you could just as easily have another frontend app generated with the help of an LLM and plug it in to the FastApi back end.
- The data matching logic is simplistic, but can be easily extended.
Conclusion
-
Building agentic applications with the help of an LLM, in this case Claude Code, is a massive productivity gainer in any enterprise. Specifically if you know what you want from a technical -and business requirements point of view, and this set of skills combined is what I believe wil define the new era of successful “AI Engineers”. Have the T shaped skills reference in mind, as the ones who can cross multiple knowledge domains will be super empowered with the use of AI. There is no excuse anymore to deliver as of today at the bare minimum PoC’s and MVP’s a magnitude faster then what most people and companies are used to. The feedback loop of iteratively writing a specification, building a solution and validating and updating a specifiation has been drastically reduced, which makes it possible to put a solid foundation of a product in place with a common understanding supported across all relevant parties involved a lot faster and cheaper. The impact is already felt and it will excellarate.
-
Balancing between code that is determistic to generate data output with LLM outputed data is an important one to think through. It could save you potentially a lot of money to have trivial deterministic data processing steps been done upfront before you rely on the LLM and burn through your tokens. And as well, doing the proper data prep work upfront before consulting a LLM is necessary to put the necessary controls and guardrails in place to deal with data security.
-
Data quality is still relevant as ever in the AI space as stated by many data professionals. For sure it becomes even more important to govern your data as your truly proprietary digital asset in the age of AI as due time the software stack will be mostly commoditized by LLM’s. But LLM’s make it possible to help you as well in creating and managing a foundation of high quality contextualized data more effectively and efficiently going forward to thrive in the agentic age. Creating and safeguarding your data assets is what will set you apart from the others your collaborate with or compete against. I will elaborate in a next write up how concepts like Data Products described in Data Mesh can be leveraged to put such a data foundation in place.
-
We will showcase as well how an agentic solution can be used to have data engineering work automated. From design, build, test to deployment and optimization for performance and costs of pipelines in production. Stay tuned.
Check out the full documentation, all generated by Claude, and the code base at GitHub